
AMD Zen 6: ISA con AVX-512 FP16, VNNI INT8, nuevos CCX y una hoja de ruta que apunta alto
Las primeras pistas sólidas de AMD Zen 6 no llegaron desde un escenario con focos, sino desde donde se cuece la compatibilidad real: un parche del compilador GCC titulado “Add AMD znver6 processor support”. Este cambio no es un benchmark ni un anuncio comercial, pero sí define el terreno de juego para desarrolladores: qué instrucciones podrán aprovechar y cómo perfilar código para la próxima generación. En paralelo, ha aparecido un nuevo CPU ID asociado a Zen 6 (B80F00), otra señal de que los distintos miembros de la familia ya están en validación.
El parche enumera cuatro extensiones clave: AVX512_FP16, AVX_NE_CONVERT, AVX_IFMA y AVX_VNNI_INT8. El mensaje es claro: más empuje a mixed precision, aceleración de inference en enteros y una cobertura AVX-512 más amplia. No es una revolución de marketing; es una caja de herramientas más completa para que software de IA, multimedia, emulación y ciencia se ejecute mejor en CPU.
Por qué importan estas instrucciones
AVX-512 FP16 añade soporte nativo de half-precision (16 bits) en vectores amplios. Cuando el algoritmo tolera menos precisión – inferencia en tiempo real, ciertos efectos de vídeo, físicas de juegos, emuladores, kernels HPC concretos – pasar de FP32 a FP16 reduce el volumen de datos, mejora el throughput y libera ancho de banda. No sustituye a FP32 en todos los casos, pero sí ofrece un camino eficiente y estándar cuando la precisión total no aporta valor.
AVX_VNNI_INT8 acelera los patrones mul-acc típicos de redes cuantizadas a 8 bits, base de muchos LLM y CNN para on-device AI. AVX_IFMA (fused multiply-add entero) y AVX_NE_CONVERT (conversiones vectorizadas) completan el conjunto, simplificando bibliotecas que hoy dependen de rutas ad-hoc o intrínsecos específicos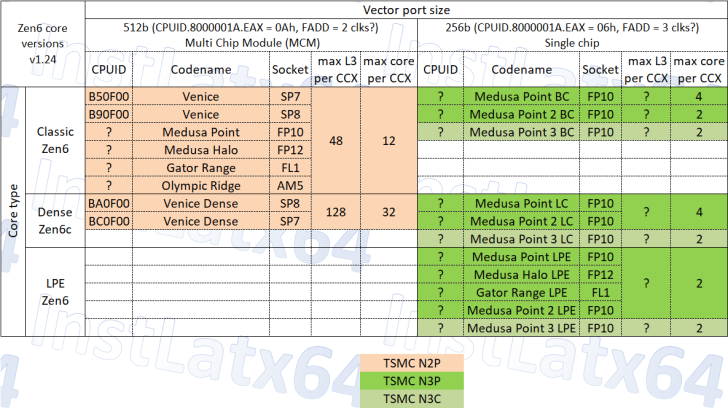
. Traducido: menos fricción para compilar un mismo código en varias máquinas y mejores latencias cuando la CPU asume tareas de IA.
Servidores: EPYC “Venice” en dos sabores, Classic y Dense
En el centro de datos, Zen 6 apunta a la familia EPYC “Venice” con dos variantes bien diferenciadas. Los identificadores actuales dibujan el mapa: Classic con SP7 “B50F00” y SP8 “B90F00”; Dense con SP7 “BC0F00” y SP8 “BA0F00”. La diferencia clave está en la granularidad de los Core Complex (CCX): hasta 12 núcleos por CCX en Classic y hasta 32 núcleos por CCX en Dense. Con un techo de plataforma de 256 núcleos (ocho CCX al máximo), la versión Dense también impresiona por caché: 128 MB de L3 por CCX, que suman hasta 1.024 MB de L3 en el paquete completo. Para cargas paralelas – analytics en memoria, consolidación de microservicios, OLAP, virtualización – tanta “memoria cerca del cómputo” puede suavizar colas y picos de latencia.
Obviamente, la magia real dependerá de latencias de L3, política de prefeteo, ancho de banda de la fabric, frecuencias sostenidas y límites térmicos. Pero la dirección es inequívoca: muchos núcleos, cachés grandes y una alimentación de datos a la altura.
Cliente: Olympic Ridge, Gator Range y la dupla Medusa
Zen 6 no se queda en el servidor. En el escritorio AM5, Olympic Ridge apunta a hasta 24 núcleos y 48 hilos (CCX de 12 núcleos con 48 MB de L3 cada uno). Para portátiles entusiastas, encaja Gator Range, mientras que los APU se reparten entre Medusa Point y Medusa Halo. Las configuraciones MCM (chiplets) se esperan en TSMC N2P, mientras que los monolíticos de Medusa Point y Gator Range optarían por TSMC N3P/N3C. Es una estrategia híbrida: chiplets cuando escalar CPU manda, monolito cuando integrar GPU, multimedia y (posible) NPU paga mejor.
Tiempos y expectativas realistas
El soporte en compiladores suele llegar muchos meses antes del silicio. Puede que AMD deje caer pinceladas en su Financial Analyst Day, pero hoy las predicciones razonables sitúan los anuncios de calado en torno al CES 2026. La clave, hasta entonces, es vigilar toolchains: cuando GCC/Clang documenten -march=znver6 y bibliotecas como BLAS/oneDNN, motores de juego o emuladores habiliten rutas FP16/INT8, sabremos que el ecosistema está listo para shipping.
Los debates de siempre, con contexto
“¿Zen 6 llega muerto?” Un parche confirma capacidades, no IPC, frecuencias, consumo ni curvas de eficiencia. Sentenciar sin datos es ruido.
“AVX-512 no sirve al usuario común.” Depende del usuario y del software. Emulación, transcodificación, VM densa y, cada vez más, IA local se benefician. FP16 y VNNI INT8 acortan la distancia con los aceleradores y, en ciertos casos, permiten resolver todo en CPU con buena latencia.
“¿AMD copia a Intel?” La historia de x86 está repleta de cross-licensing y evolución convergente. Los desarrolladores quieren primitivas comunes porque facilitan portar y mantener software. La convergencia en ISA no es plagio; es pragmatismo de ecosistema.
“¿Y Nova Lake?” La competencia es el combustible. Si Nova Lake llega fuerte, mejor para el mercado; si Zen 6 responde en la misma medida, también. Resultado: más rendimiento por vatio y mejores precios.
Qué vigilar si eres usuario o dev
- Flags de compilación como
-march=znver6y-mtune=znver6en GCC/Clang, y notas en changelogs. - Commits en motores y emuladores activando rutas FP16/INT8 en los hot loops.
- Primeras SKUs EPYC Venice con el reparto de CCX, cachés, clocks sostenidos y perf-per-watt bajo carga continua.
- En APU, cómo cooperan CPU, GPU y posibles NPU: scheduling, memoria compartida y costos de traspaso.
Con todo lo anterior, Zen 6 pinta como una arquitectura pensada para el presente: software con “toque” de IA, paralelismo agresivo y necesidad de primitivas vectoriales portables. No jubilará a los aceleradores, pero sí subirá el listón de lo que tu CPU puede hacer con resultados ágiles y consistentes en el día a día.
1 comentario
Nova Lake vs Zen 6: que compitan y bajen el W por rendimiento. Mi cartera lo agradece 😅